In-memory analytics
In-memory analytics refers to business intelligence tool that utilizes an in-memory (RAM) for data processing. In-memory analytics is used to solve complex and time-sensitive business scenarios in BI and it increases the speed, performance and reliability when querying data. In-memory analytics helps to improve the overall speed of a BI system and provides business-intelligence users with faster answers compared to traditional disk-based business intelligence, especially for queries that take a long time to process in a large database.
When we say something is in-memory, it means residing in the Random Access Memory (RAM) against the disk. For a CPU to do some data processing, the data needs to be in-memory and if the data is already is in-memory then we can avoid the usual slow disk I/O, making the in-memory computing a pretty fast process. Accessing data in memory eliminates seek time when querying the data, which provides faster and more predictable performance than disk.
A potential technical hurdle with in-memory data storage is the volatility of RAM. Specifically in the event of a power loss, intentional or otherwise, data stored in volatile RAM is lost. With the introduction of non-volatile random access memory technology, in-memory databases will be able to run at full speed and maintain data in the event of power failure.
In Today’s world organization needs to perform exhaustive data collection while providing real-time analytics to leadership and the staff regardless of which platforms they use or where they geographically are located. The manufacturers have stepped up to the challenge and most provide solutions in the form of in-memory platforms instead of spinning technology-based products.
There are many In-Memory Business Intelligence Analytics Tools are available in the market and I have listed few of them which are performing well in in-memory processing.
SAP HANA
SAP HANA (High-Performance Analytic Appliance ) is an in-memory, column-oriented, relational database management system developed and marketed by . The primary function as a database server is to store and retrieve data as requested by the applications. SAP HANA includes a number of analytic engines for various kinds of data processing. In addition, it performs predictive analytics, spatial data processing, text analytics, text search, streaming analytics, graph data processing and includes ETL capabilities as well as an application server.
SAP HANA Business Function Library includes a number of algorithms which can address the c business data processing such as asset depreciation, rolling forecast and moving average and Predictive Analytics Library includes native algorithms for calculating common statistical measures in areas such as clustering, classification and time series analysis.
Oracle Exalytics In-Memory Machine
Oracle Exalytics is part of the family of Exa technology solutions which include Exadata and Exalogic. The Exalytics overcomes many BI roadblocks such as multiple vendors, support issues, performance challenges, replicated data, too many servers, user acceptance, data volumes and sizing, lack of optimization, and system latency. Below are some Oracle Exlaytics product overviews.
• Faster, deeper reporting and insights
• Instantaneous response times
• Self-service data discovery
• Consolidate your business analytics
• Oracle Endeca Information Discovery
• TimesTen In-Memory Database
• Optimized with Oracle Exadata
• Powered by -Intel processors and leverages Oracle Linux
Microsoft SQL Server / Azure SQL in-memory database
SQL Server provides In-Memory features that can greatly improve the performance of many application systems. In-Memory Analytics refers to SQL SELECTs which aggregate transactional data, typically by inclusion of a GROUP BY clause. The index type called columnstore is central to operational analytics. By using In-Memory technologies in Azure SQL Database, we can achieve performance improvements with various workloads like transactional (online transactional processing (OLTP)), analytics (online analytical processing (OLAP)), and mixed (hybrid transaction/analytical processing (HTAP)). Because of the more efficient query and transaction processing, In-Memory technologies also help you to reduce cost.
IBM DB2 in-Memory Database
IBM DB2 is powerful multi-workload database software that powers the next generation of applications including mobile, advanced analytics, cognitive and highly available transactions. IBM DB2 offers a security-rich environment required for the hybrid world, designed to protect data both in flight and at rest. It also scales to new heights of performance by enabling its in-memory technology to be easily deployed across MPP architecture and helping to dramatically improve response times.
MicroStrategy Intelligence Server
MicroStrategy Intelligent Cubes are multi-dimensional cubes that allows users to use the OLAP
Services features on reports, as well as share sets of data among multiple reports. An Intelligent Cube is a set of data that can be shared as a single in-memory copy, among many different reports created by multiple users. Rather than returning data from the data warehouse for a single report, you can return sets of data from your data warehouse and save them directly to Intelligence Server memory. The reports accessing Intelligent Cubes can use all of the OLAP Services features for analysis and reporting purposes.
QlikView’s in-memory
QlikView’s in-memory data structures are quite simple. QlikView data is stored in a straightforward tabular format and data is compressed via what QlikTech called as “dictionary” or “token” compression. QlikView typically gets data via scans and there is very little in the way of precomputed aggregates, indexes, and the like. Of course, if the selection happens to be in line with the order in which the records are sorted, you can get great selectivity in a scan. QlikView holds its data in nice arrays, so the addresses of individual rows can often be easily calculated.
SAS in-Memory Statistics
SAS In-Memory Statistics gives multiple users the ability to simultaneously analyze huge volumes of data. This, combined with very powerful analytical techniques, provides an unprecedented way to tap into big data to quickly derive insights for high-value analytical decisions. Dramatically reducing model development time means more models can be put in action sooner.
TIBCO ActiveSpace In-Memory Computing
In-memory computing with TIBCO ActiveSpaces provides a distributed, scale-out, in-memory data grid, delivering a consistent, fault-tolerant database that supports scalability for mixed TIBCO ActiveSpaces Delight customers and make better decisions With ActiveSpaces, contextual, reference, and operational data normally housed in back-end applications can be stored in-memory for lightning fast performance that leads to delighting customers and beating the other guys. ActiveSpaces draws on available server memory but also stores to local disk for data safety and for scaling to handle processing of the largest data volumes.
Tableau Data Extract (TDE) in-memory Analysis
A Tableau data extract is a compressed snapshot of data stored on disk and loaded into memory as required to render a Tableau viz. There are 2 important aspects of TDE design which supports analytics and data discovery in Tableau. TDE uses “Columnar Store” and unlined design of “Architecture Aware”. architecture-awareness means that TDEs use all parts of your computer’s memory, from RAM to hard disk, and put each part to work as best fits its characteristics.
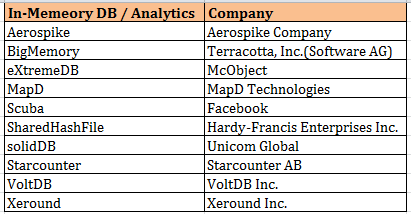
Below are some of other in-memory analytic databases / tools.
In-Chip technology
In-memory alone isn’t enough to fix BI’s data loading problem. Rather, you need a smart solution that combines the best of disk and RAM and that brings us to In-Chip technology.
Sisense introduced an alternative to in-memory technology called In-Chip analytics designed to maximize the disk, memory and CPU with resulting low latency. Sisense unveiled Prism 10X, which allows users to analyze 100 times more data at 10 times the speed of in-memory solutions. The company’s In-Chip Analytics technology couples a columnar database with smart algorithms that use the in-chip cache, RAM or disk as needed instead of relying solely on RAM or disk.
Sisense introduced Crowd Accelerated BI a technology that allows companies to scale users by providing faster query results as load increases and scale to thousands of simultaneous users on a single box
Each query is broken down to its basic components, which then helps the software decide which data to store on disk and which data to bring to memory. As more queries are catalogued, the software is able to more quickly recognize future similar queries and call up relevant data. Later the company launched Sisense 5, a redesign of Prism which included improvements such e-mail push notifications and the ability to analyze big data over tablets and smartphones (source: Wiki)
To know more about Sisense in-Chip technology, click here.
In-Chip Technology Revoultionzed Analysis
You can learn more about sisense here
